import pandas as pd
import numpy as np
df_salary = pd.read_csv('bucketing.csv', header=0)
df_salary.head()
(109516, 2)
BUCKET_SIZE = 10000 # the difference between lower and upper ranges in each bucket
BUCKET_LOWER_LIMIT = 10000 # the bucket starts here
BUCKET_UPPER_LIMIT = 250000 # the bucket ends here
BUCKET_UNITS = 1000 # the bucket range will be in 1000s
BUCKET_STRING_LENGTH = 3 # prepend zeroes to make the label of length 3
col = 'SALARY'
conditions = []
choices = []
conditions.append(df_salary[col].le(BUCKET_LOWER_LIMIT))
choice_str = '<=' + str(int(BUCKET_LOWER_LIMIT/BUCKET_UNITS)).zfill(BUCKET_STRING_LENGTH)
choices.append(choice_str)
current_value = BUCKET_LOWER_LIMIT
next_value = None
while current_value < BUCKET_UPPER_LIMIT:
next_value = current_value + BUCKET_SIZE
if next_value > BUCKET_UPPER_LIMIT:
break
conditions.append(df_salary[col].between(current_value, next_value))
choice_str = str(int(current_value/BUCKET_UNITS)).zfill(BUCKET_STRING_LENGTH) + '-' + str(int(next_value/BUCKET_UNITS)).zfill(BUCKET_STRING_LENGTH)
choices.append(choice_str)
current_value = next_value
##--------------------------------------------------------------------------------------------------------
## crossing the upper limit may omit a bucket in-between
if next_value > BUCKET_UPPER_LIMIT:
current_value = next_value - BUCKET_SIZE
next_value = BUCKET_UPPER_LIMIT
conditions.append(df_salary[col].between(current_value, next_value))
choice_str = str(int(current_value/BUCKET_UNITS)).zfill(BUCKET_STRING_LENGTH) + '-' + str(int(next_value/BUCKET_UNITS)).zfill(BUCKET_STRING_LENGTH)
choices.append(choice_str)
##--------------------------------------------------------------------------------------------------------
conditions.append(df_salary[col].gt(BUCKET_UPPER_LIMIT))
choice_str = '>' + str(int(BUCKET_UPPER_LIMIT/BUCKET_UNITS)).zfill(BUCKET_STRING_LENGTH)
choices.append(choice_str)
print('Buckets: ', choices)
df_salary['BUCKET'] = np.select(conditions, choices, default=np.nan)
Buckets: ['<=010', '010-020', '020-030', '030-040', '040-050', '050-060', '060-070',
'070-080', '080-090', '090-100', '100-110', '110-120', '120-130', '130-140', '140-150',
'150-160', '160-170', '170-180', '180-190', '190-200', '200-210', '210-220', '220-230',
'230-240', '240-250', '>250']
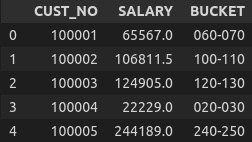
## The order of conditions is such that the border values
## (multiples of the bucket size) will be considered in the lower bucket.
## eg. 50000 will take '040-050' and not '050-060'
df_salary.loc[(df_salary['SALARY']%BUCKET_SIZE == 0)]
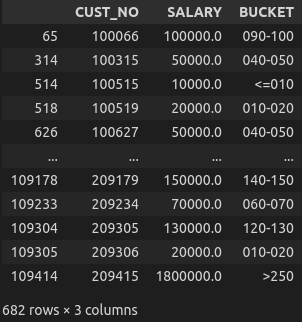
df_salary.groupby(['BUCKET']).size()